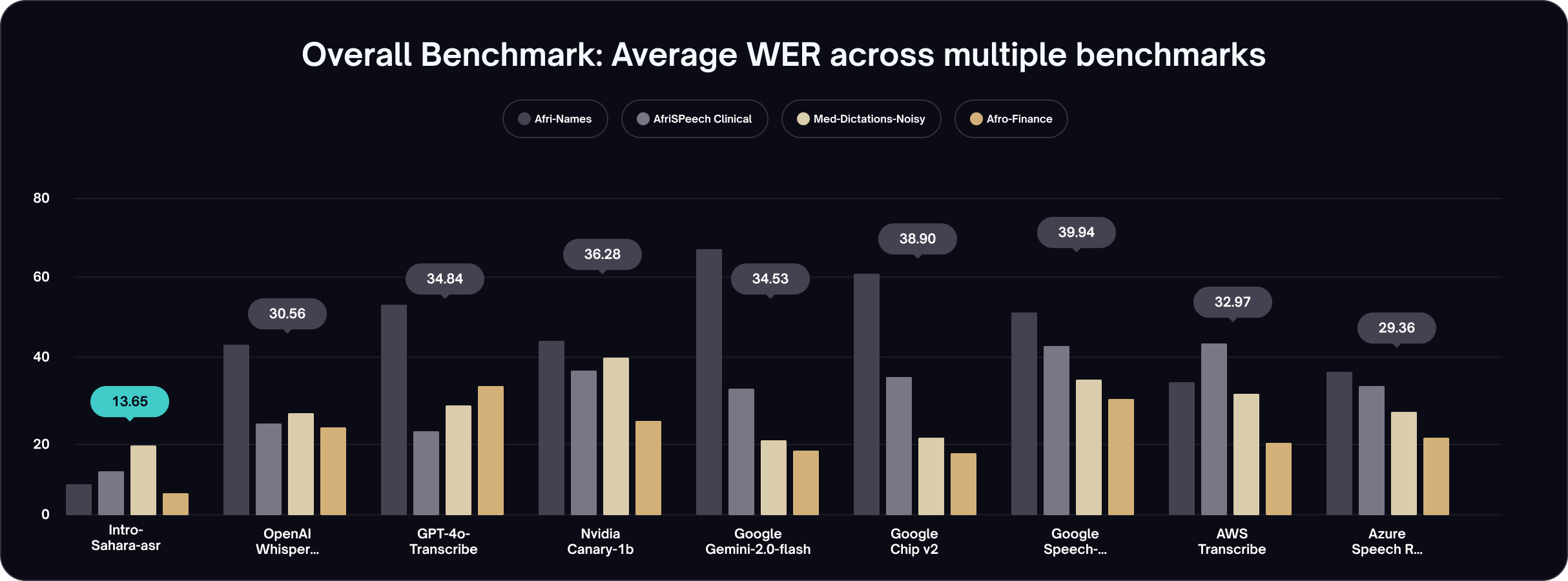

intron-sahara-asr
general purpose cross-domain speech recognition model
intron-sahara-stream
streaming model optimised for medical conversations
intron-sahara-voice-lock
biometric voice-based authentication tuned for African accents and languages to combat fraud
intron-sahara-asr
general purpose cross-domain speech recognition model
intron-sahara-stream
streaming model optimised for medical conversations









