


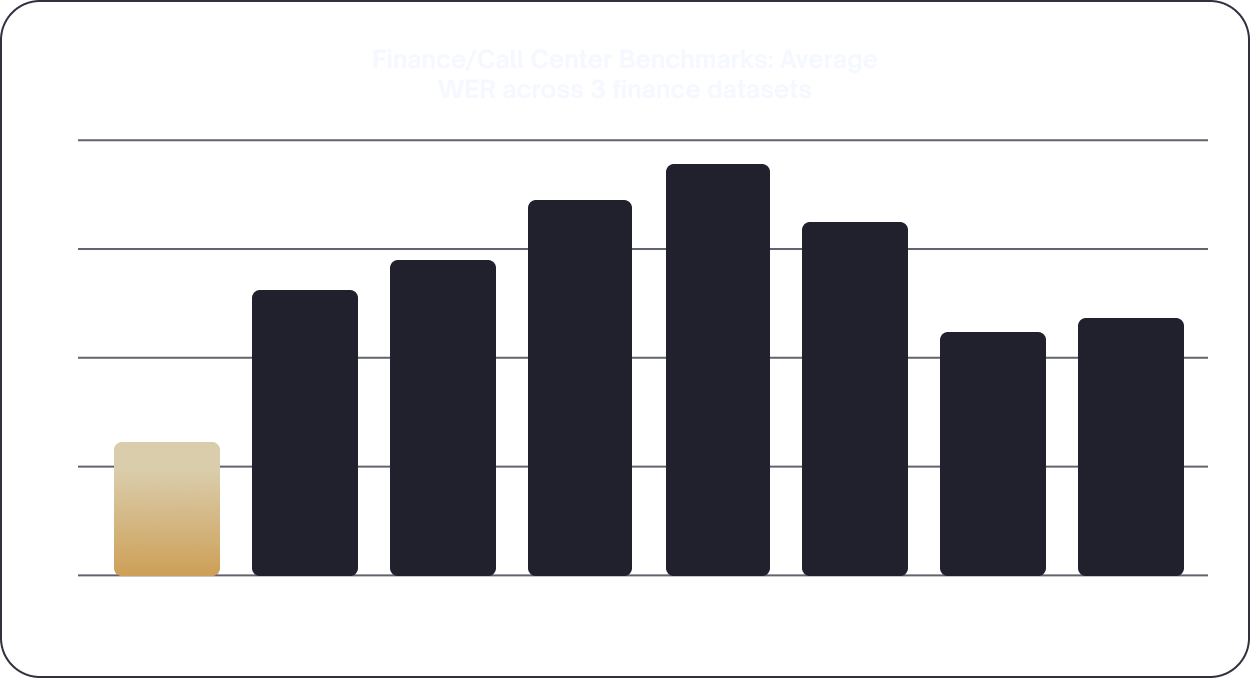


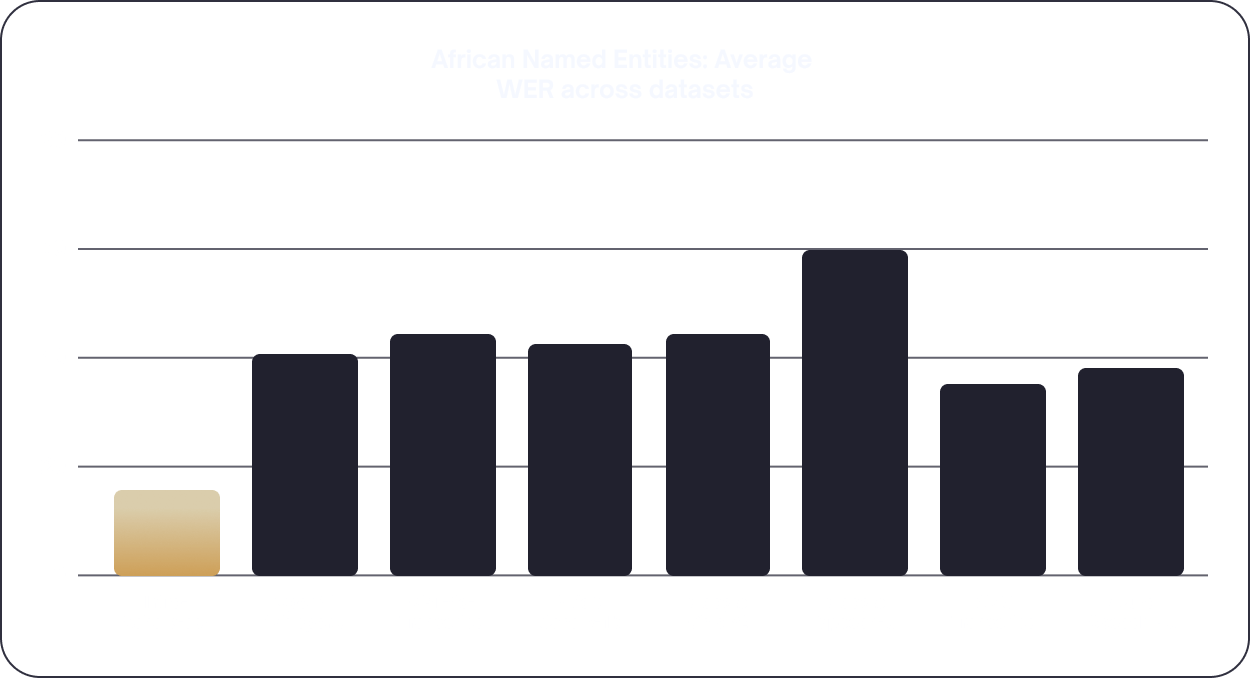

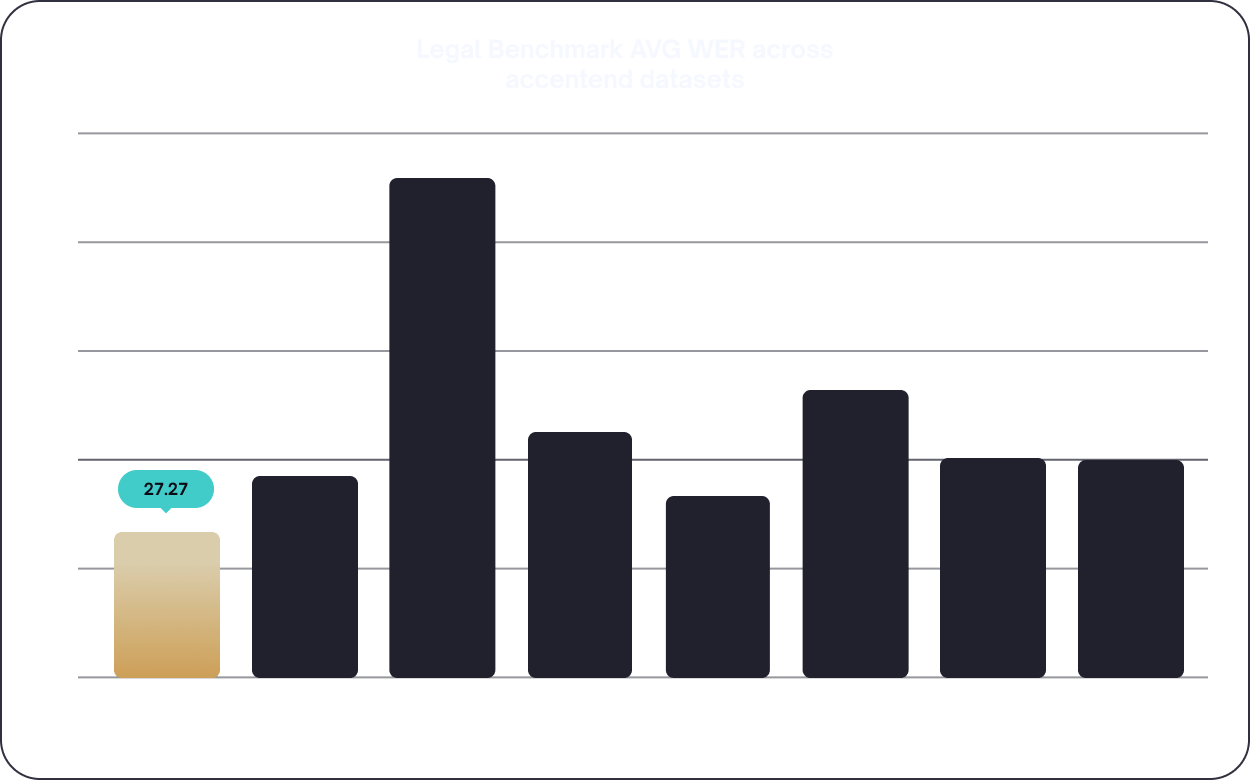


our flagship general-purpose cross-domain speech recognition model optimised for African accents

A lightweight streaming model optimised for speed, real-time transcription, and medical conversations

biometric voice-based authentication tuned for African accents and languages to combat fraud and deepfakes

the first speech synthesis model with 80+ female/male voices, in 40+ African accents spoken across 13 countries

SOTA multilingual automatic speech translation and transcription model on 20 African languages
our flagship general purpose cross-domain speech recognition model optimized for African accents
a lightweight streaming model optimised for speed, real-time transcription, and medical conversations
biometric voice-based authentication tuned for African accents and languages to combat fraud and deepfakes
first production pan-African accented speech synthesis model with 80+ female/male voices in 40+ African accents spoken across 13 countries
SOTA multilingual automatic speech translation and transcription model on 20 African languages